
Cộng đồng AI lại vừa có một phen "chấn động" khi Alibaba tung ra Qwen3-Coder-Next. Nếu bạn nghĩ Qwen 2.5 đã ngon rồi, thì phiên bản này đúng là một cú nhảy vọt. Điều điên rồ nhất? Nó là một con quái vật 80B tham số nhưng lại tối ưu đến mức có thể chạy mượt trên máy cá nhân (nếu máy bạn đủ khỏe).
Hôm nay, hãy cùng mình "mổ xẻ" xem em hàng này có gì hot và liệu nó có soán ngôi được các ông lớn hiện tại không nhé! 👇
Kiến Trúc MoE: "Hack" Hiệu Năng Cực Đỉnh 🧠
Điểm ăn tiền nhất của Qwen3-Coder-Next chính là kiến trúc Mixture-of-Experts (MoE).
Giải thích nhanh cho bạn nào chưa biết: Thay vì kích hoạt toàn bộ bộ não 80 tỷ tham số cho mỗi từ (token) nó sinh ra, model này chỉ dùng đúng 3 tỷ tham số cần thiết nhất.
👉 Tưởng tượng thế này: Bạn có một thư viện 80,000 cuốn sách (80B params). Nhưng khi bạn hỏi về code Python, nó chỉ lôi đúng 3,000 cuốn sách về Python ra đọc thôi. Kết quả? Thông minh như model khổng lồ, nhưng nhanh và nhẹ như model nhỏ.
"Agentic" - Không Chỉ Là Code Completion 🤖
Mình thấy xu hướng năm 2026 này không còn là Chatbot nữa mà là AI Agents. Qwen3-Coder-Next được training đặc biệt để làm việc này.
Nó không chỉ điền nốt dòng code bạn đang viết dở (code completion), mà nó có thể:
- Hiểu và thực hiện các tác vụ dài hơi (long-horizon tasks).
- Tự biết dùng tools, debug khi gặp lỗi.
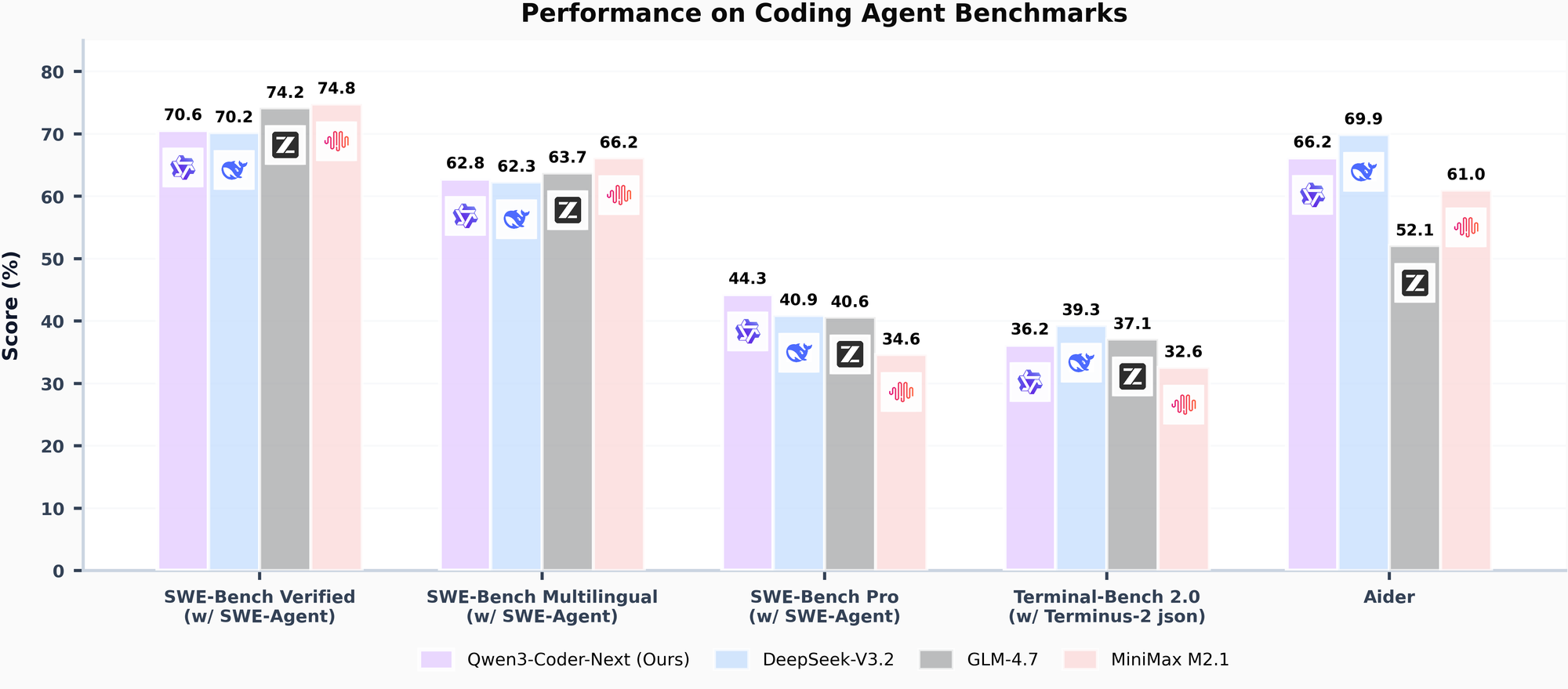
- Đạt điểm SWE-Bench Verified > 70% (ngang ngửa DeepSeek V3.2 và GLM-4.7).
Điều này có nghĩa là bạn có thể vứt cho nó một cái issue trên GitHub và bảo "Fix đi", khả năng cao là nó tự mò code, sửa lỗi và tạo PR luôn.
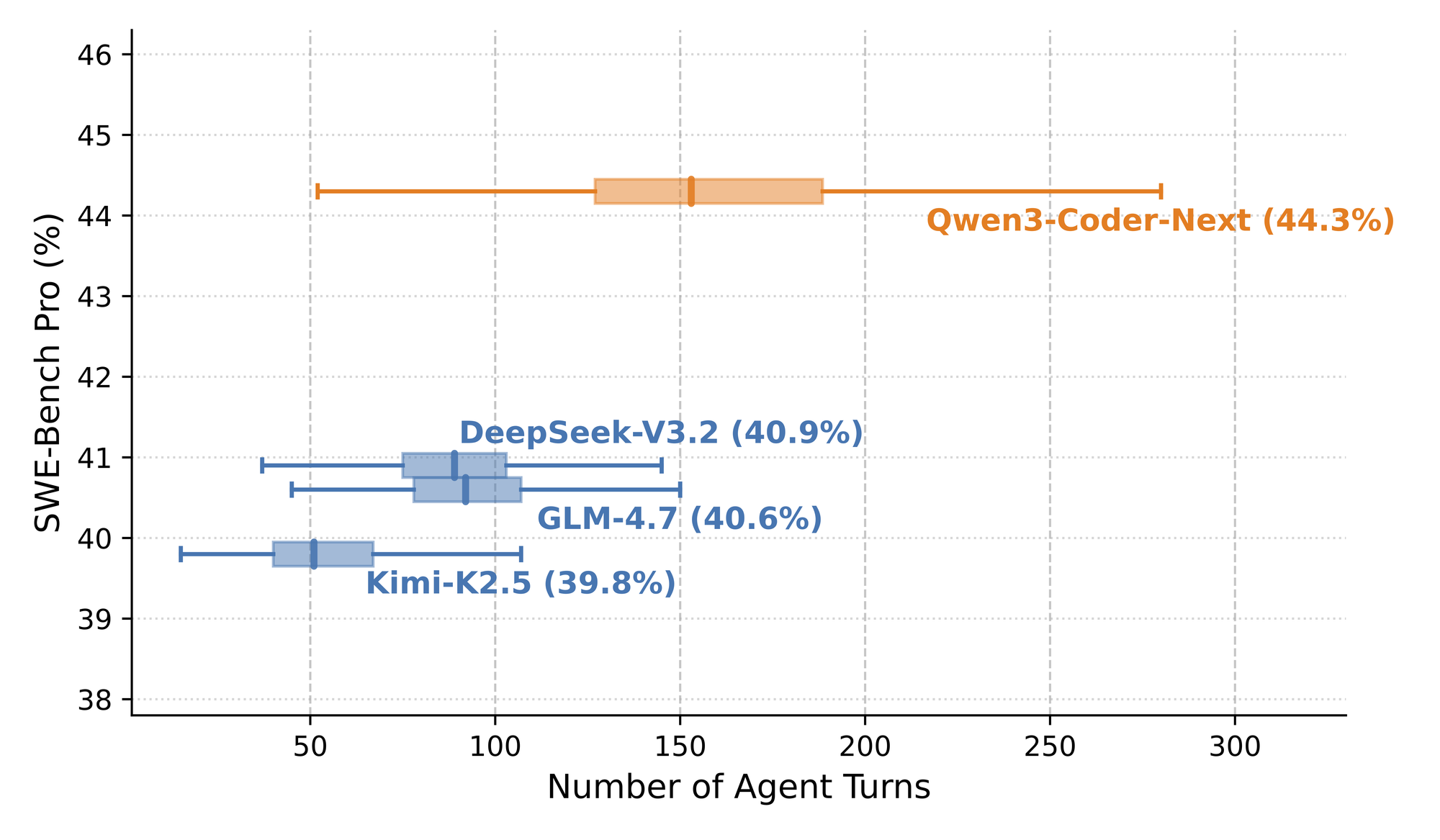
Cấu Hình Để "Nuôi" Quái Vật? 💻
Đây là phần anh em quan tâm nhất nè. 80B nghe thì sợ, nhưng nhờ MoE và lượng active params thấp, yêu cầu phần cứng của nó "khá thở" so với kích thước.
Theo thông số benchmark:
- 4-bit Quantization: Cần khoảng 46GB VRAM/RAM.
- 8-bit Quantization: Cần khoảng 85GB VRAM/RAM.
👉 Kèo thơm cho team Mac Studio: Nếu bạn đang dùng Mac Studio M2/M3 Max (64GB RAM) hoặc Ultra, bạn hoàn toàn có thể chạy bản 4-bit mượt mà. Với anh em PC, combo Dual RTX 3090/4090 (24GB x 2) là chiến tốt.
So với việc phải thuê server A100 tốn kém, thì việc chạy local một model mạnh cỡ này là một giấc mơ thành hiện thực.
| Model | Size | Active Params | Yêu cầu VRAM (4-bit) |
|---|---|---|---|
| Qwen3-Coder-Next | 80B | ~3B | ~46 GB |
| DeepSeek V3 | 671B | 37B | Server-grade |
| Llama 3 70B | 70B | 70B | ~40 GB |
Lưu ý: Qwen3 dùng MoE nên tốc độ infer sẽ nhanh hơn Llama 3 70B nhiều dù VRAM xêm xêm.
So Sánh Với Đối Thủ 🥊
Trên bảng xếp hạng SWE-Bench Verified:
- Qwen3-Coder-Next: ~70.6%
- DeepSeek V3.2: ~70.2%
- GLM-4.7: ~74.2%
Nó đang đứng chung mâm với những model mạnh nhất thế giới hiện tại. Đặc biệt ở khoản Multilingual (đa ngôn ngữ), Qwen vẫn luôn làm rất tốt khoản tiếng Trung và tiếng Anh, và giờ là cả tiếng Việt cũng khá mượt (dù vẫn cần prompt kỹ một chút).
Kết Luận: Tải Ngay Kẻo Lỡ! 🔥
Alibaba Qwen3-Coder-Next thực sự là một cú hích lớn cho cộng đồng Open Source / Open Weight. License Apache 2.0 cho phép dùng thương mại thoải mái cũng là một điểm cộng siêu to khổng lồ.
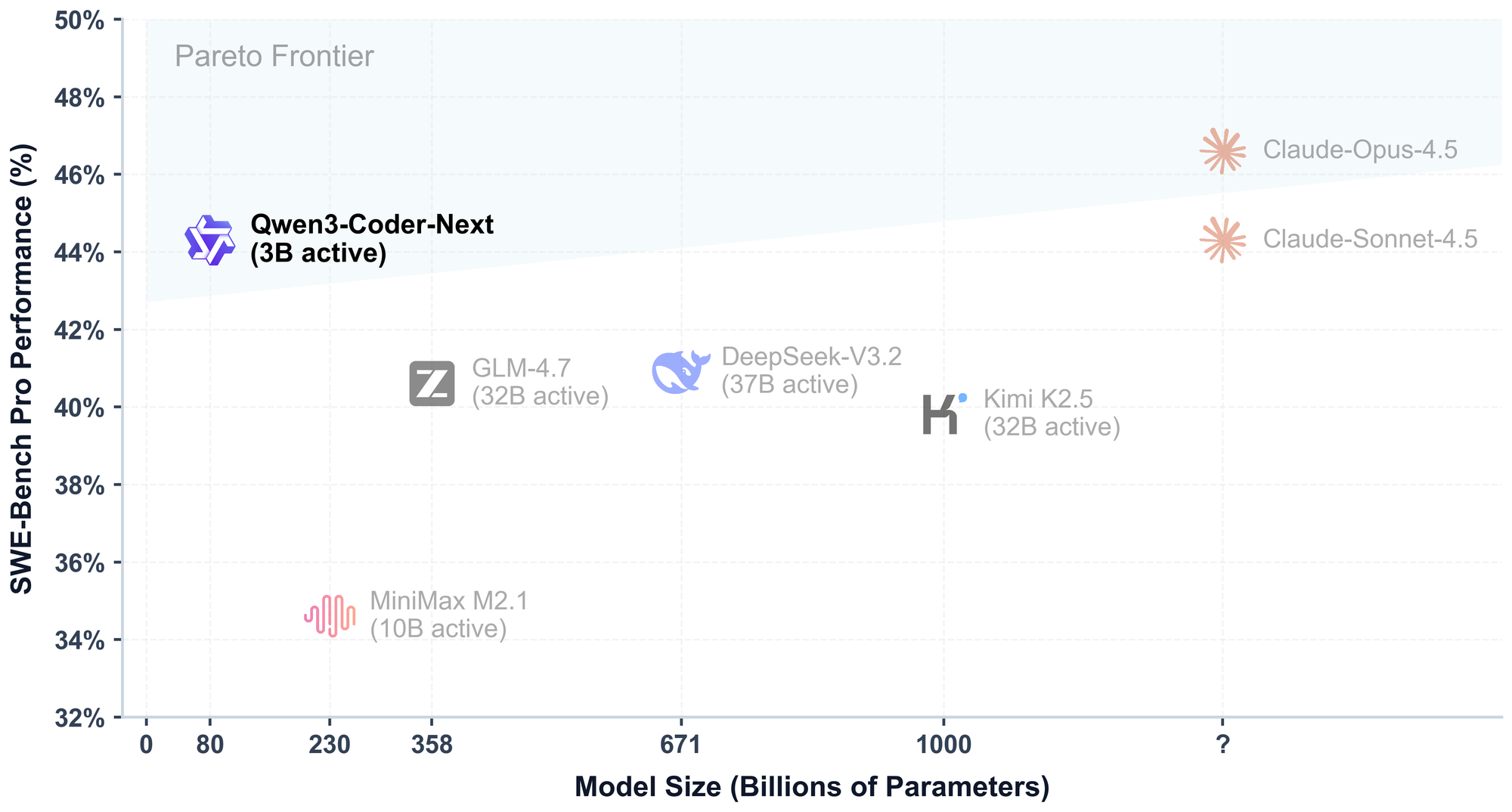
Nếu bạn là dev, thích vọc vạch local LLM và có một con máy đủ khỏe, không có lý do gì để không thử ngay em này.
🔗 Link tải model: Hugging Face
🔗 Chạy thử API: OpenRouter
Bạn nghĩ sao về model này? Có định nâng cấp RAM để "nuôi" em nó không? Comment chém gió với mình nhé! 👇
Discussion